第四章 推导与生成
1.用列表推导取代map与filter
python中可以根据某个序列或可迭代对象派生出一份新列表,称为列表推导:

它还可以过滤原列表,把某些输入值对应的计算结果从输出结果中排除:

相当于同时使用了map与filter,但是比那种写法要更易懂

字典与集合也有相应的推导机制,分别叫做字典推导与集合推导

2.控制推导逻辑的子表达式不要超过两个
列表推导支持多层循环,例如将二维列表转换为一维:

多层循环也可以用来设置两层深的结构

但是更深的层次会导致列表推导过于难懂,不如直接使用for循环构造:


顺带一提,多个if条件在同一级别是and关系:

在表示推导逻辑时,最多之应该写两个子表达式(例如两个if条件、两个for循环、或者一个if条件与一个for循环)。只要实现的逻辑比这个要复杂,就应该采用普通的if与for语句实现,并可以考虑编写辅助函数。
3. 用赋值表达式消除推导中的重复代码

假设要对订单中每个货物以8个一批的方式发货,并要判断货物库存是否能够够一批标准,通过order与stock的相同字段来进行匹配。

这里调用了两次get_batches方法,在只更改其中一个方法时会导致方法错误。因此要使用赋值表达式来消除推导中的重复代码。


4. 不要让函数直接返回列表,应该让它逐个生成列表里的值
写一段代码来找出文本中每个单词的开头位置

改用生成器会更好,首先,会更加简洁:

其次,不用一次性构造整个列表,例如,不用先读出全文,可以每行每行递进


5. 函数在迭代参数前要先判断参数的类型
源于这样一种考量:
若传来的是一个迭代器或生成器,则只能产生一次结果,不能够遍历两边


使用list构造列表时也会出现同样问题,导致已经耗完数据的迭代器返回空列表

先copy出所有结果又会导致数据过多,从而有内存崩溃的风险

因此最好的方式是在函数的两次迭代sum(numbers)与for value in numbers中每次都先拿到一个新的迭代器:


python中提供了一个接口用于实现迭代器协议(iterator protocol):
Python执行for x in foo这样的语句时,实际上会调用iter(foo),也就是把foo传给内置的iter函数。这个函数会触发名为foo.__iter__的特殊方法,该方法必须返回迭代器对象(这个迭代器对象本身要实现__next__特殊方法)。最后,Python会用迭代器对象反复调用内置的next函数,直到数据耗尽为止(如果抛出StopIteration异常,就表示数据已经迭代完了)。
因此只需要新建一个容器类:
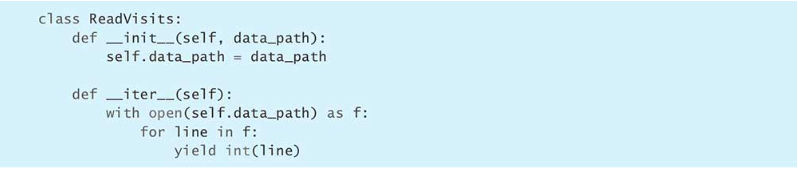
所以,在编写函数处理迭代时,最好先检查一下迭代的类型,防止在函数中出现数据耗尽的问题,并报出TypeError错误来提示接口使用者:


6. 考虑用生成器表达式改写数据量较大的列表推导
例如读写文件时,直接使用列表推导需要将文件中的每行文本都载入内存,对于庞大的文件会导致内存耗尽。

要想处理大规模数据,可以使用生成器表达式,生成器表达式每次给出一个结果:

同时生成器表达式还可以进行嵌套:

使用时可以用内置的next函数取得结果:

但是要注意迭代器在跑完一轮后会导致数据耗尽,无法继续使用,此时需要新生成一个迭代器。
7.通过yield from连接多个生成器


连接多个生成器可以采用上面的方式,采用多个for遍历。

可以改成使用yield from来简化,且这种方式速度更快,因此优先使用yield from来连接生成器:

8. 不要用send给生成器注入数据
send,调用send方法时传入的参数会成为上一条yield表达式的值,生成器拿到这个值后,推进到下一条yield。在刚开始推进生成器时,是从头执行的,而不是从某一条yield继续,因此首次调用时只能传None。

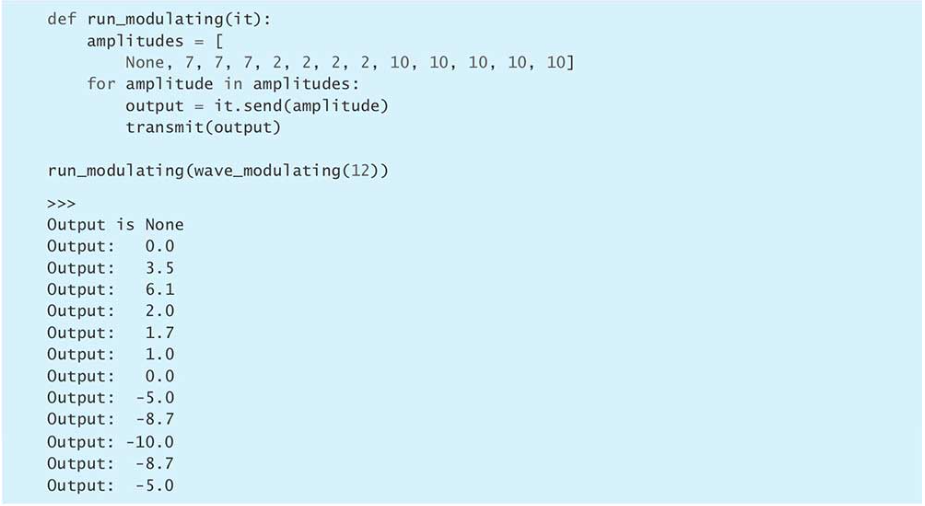
由于这种逻辑上的复杂性,这样写会导致代码可读性较差,因此应当用多个yield from来代替。


9. 不要通过throw变换生成器的状态
通过iter.throw为生成器注入异常,则异常会被重新抛出。

这样的方式通常被用来改变生成器的状态,例如如下的一个计时器的重置。


然而这样的双向通信逻辑复杂,不如采用如下的一个可迭代的容器对象:


10. 考虑用itertools拼装迭代器与生成器
如果要实现比较难写的迭代逻辑,可以查看itertools文档,去查找可能用得到的函数。
这些函数分为三大类:
连接多个迭代器
chain
chain可以把多个迭代器从头到尾连接成一个迭代器。

repeat
repeat可以不停地输出某个值:

cycle
cycle可以循环地输出各项元素:

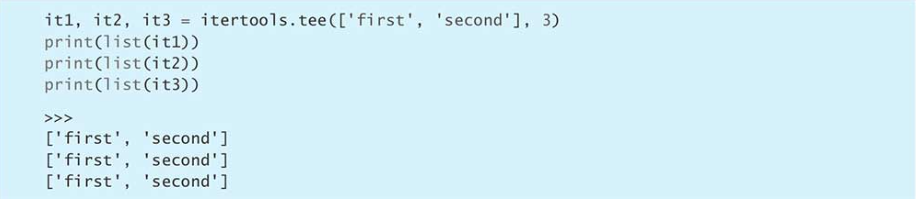
tee
分裂多个平行的迭代器,每个迭代器推进的速度可能不一致
zip_longest
与zip类似,如果长度不同,会用fillvalue来填补耗尽的那些迭代器留下的空缺:

过滤源迭代器中的元素
islice
按照下标切割源迭代器,给出起点、终点、步进值。

takewhile
一直获取元素,直到某元素让测试函数返回False为止。

dropwhile
会一直跳过元素,知道某个元素让测试函数返回True为止,然后开始逐个取值。

filterfalse
与filter相反,逐个返回False的那些元素

用源迭代器中的元素合成新元素
accumulate
取出元素,与累加结果一起传给表示累加逻辑的函数,然后输出那个函数的计算结果作为新的累计值。

product
获取元素计算笛卡尔积,可以取代那种多层嵌套的列表推导代码:

permutations
输出所有有序排列,如果元素相同但顺序不同算两种排列。

combinations
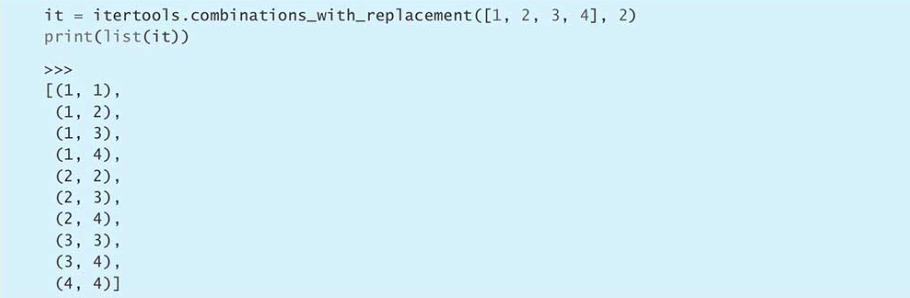
所有无序排列,即如果元素相同但顺序不同算同一种组合:

combinations_with_replacement
可放回的排列,允许同一个元素在组合里多次出现。